
Autory článku jsou Lukáš Jelínek a Miroslav Hrončok. Není-li uvedeno jinak, je autorem fotografií Tomáš Vondra, jehož fotografie z akce jsou dostupné pod licencí CC BY-SA. Více jich najdete v galeriích z pondělí a úterý, středy, čtvrtku i pátku. Nezpomeňte si přečíst reportáž ze středy a ze čtvrtka.
PostBIS – a bioinformatics booster for PostgreSQL
Michael Schneider
Jednou z dynamicky se rozvíjejících oblastí bioinformatiky je podpora pro genetické inženýrství. V mnoha případech se genetická data ukládají „postaru“ do obyčejných souborů, někdy se využívají NoSQL databáze (např. MongoDB), lze ale s úspěchem využít i SQL databáze, tedy v tomto případě PostgreSQL. Michael Schneider představil svůj projekt, který je součástí jeho diplomové práce zaměřené na tuto oblast.
Základním problémem je, že genetická data (sekvence DNA, případně RNA) jsou velmi objemná a jednotková cena úložného prostoru neklesá tak rychle jako jednotková cena výkonu pro generování dat k uložení. Proto je žádoucí data vhodným způsobem komprimovat – a to tak, aby pro konkrétní data (tj. posloupnost nukleových bází) dosahovala jak vysokého kompresního poměru, tak vysoké rychlosti práce s těmito daty.
PostgreSQL standardně využívá (v případě úložiště typu EXTENDED) kompresní algoritmus Lempel-Ziv, který se pro tyto účely ukázal jako nevhodný – příliš pomalý. Oproti tomu řešení PostBIS využívá dva jiné algoritmy: RLE a Huffmanovo kódování. Podle předpokládané velikosti dat lze využít jen jeden z nich nebo oba dva.
PostBIS vykazuje v praxi výtečné výsledky jak v účinnosti komprese (ta se pro dlouhé řetězce velmi blíží úrovni entropie, tedy redundace dat je extrémně nízká), tak z hlediska výkonu (řádově rychlejší než běžné univerzální kompresní algoritmy). Při hodnocení výkonu nejde jen o prostou komprimaci/dekomprimaci, ale ve velké míře i o prohledávání genetických řetězců.
 Michael Schneider
Michael Schneider
V blízké budoucnosti Michael plánuje PostBIS ještě dále vylepšit, a to především o využití referencí (různé řetězce mají často společné velmi dlouhé části), podporu indexů a v neposlední řadě přizpůsobení aplikací tak, aby dokázaly s tímto řešením optimálně pracovat.
Lukáš Jelínek
Beyond Query Logging
Greg Smith, Peter Geoghegan
Na přednášce o logování bylo nejdřív vysvětleno, proč standardní logování v plaintextu nestojí za nic – logy jsou nepřehledné, dostanete se do problémů s jejich rotací a budou vám hrozně bobtnat. Poté byla předvedena alternativa – syslog. Ten se u PostgreSQL trochu obtížně nasazuje, ale když už ho jednou rozběháte, jeho používání a čtení logů je hračka.
Pokud chcete logy analyzovat, máte na výběr z několika nástrojů: novinkou v oblasti je pgBadger, můžete ale použít i starší pgFouine pro analýzu středně velkých logů, případně pgsi nebo pg_query_analyser pro ty větší.
 Greg Smith a Peter Geoghegan
Greg Smith a Peter Geoghegan
Bylo demonstrováno, jak simulovat workload analýzu – není to úplně jednoduché, více se dozvíte třeba na slidech (PDF). Naštěstí v PostgreSQL 9.2 už je možné provádět opravdovou workload analýzu přímo.
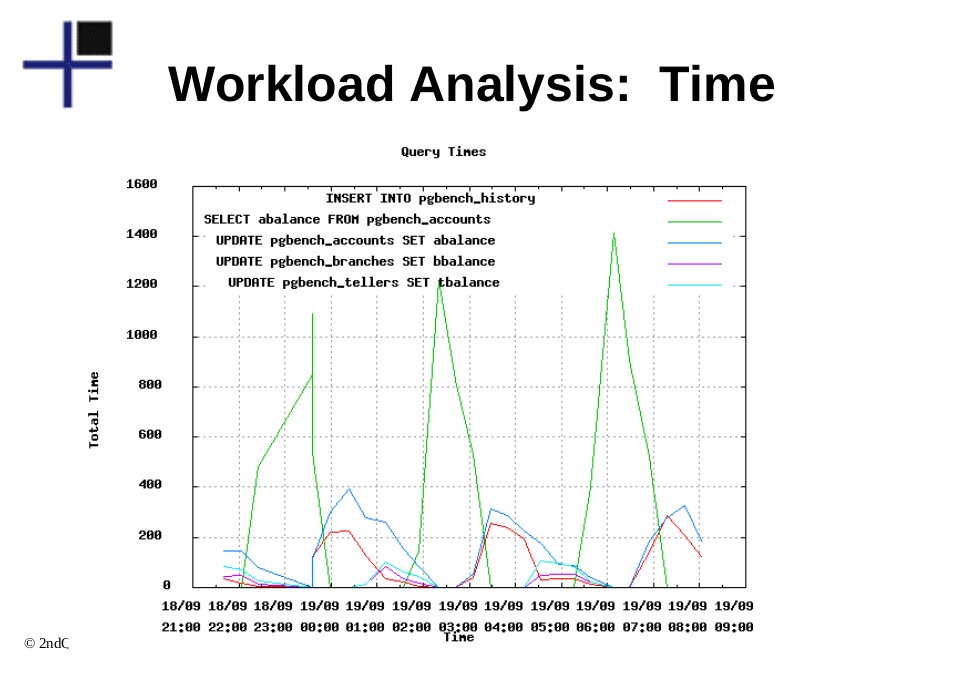 Slajd z přednášky
Slajd z přednášky
Na konci přednášky byl ještě předveden nástroj pg_stat_plans, derivát klasického pg_stat_statements, který ale na rozdíl od něj počítá s tím, že se query plan může časem měnit.
Miroslav Hrončok
Migrating Oracle queries to PostgreSQL
Alexej Kljukin
Při migraci z databázových systémů Oracle (především z těch starších, například ze stále ještě hojně se vyskytující verze 8i) na PostgreSQL bývá potřeba řešit nejen převod dat, ale také přizpůsobení aplikace, zejména dotazů. U dat je to relativně jednoduché, protože většinu datových typů existujících v Oracle má i PostgreSQL, takže stačí použít nějaký vhodný nástroj – ať již ora2pg, přenos přes CSV, nebo nové řešení pomocí FDW.
Složitější je to ale s dotazy, proto se Alexej Kljukin věnoval ve své přednášce různým záludnostem, které jsou s takovou migrací spojeny. V některých případech se složitější dotazy transformují na jednodušší (například levé, pravé či úplné vnější spojení), jindy je tomu naopak (kupříkladu hierarchické dotazy využívající CONNECT BY a další podobné), kdy je někdy potřeba obyčejný dotaz přepsat na funkci.
Jiná úskalí jsou spojena například s využitím ROWID (protože částečný ekvivalent CTID v PostgreSQL má nejen jiný formát, ale i doménu platnosti) a ROWNUM (přímý přepis dotazů na využití OFFSET a LIMIT není možný, protože ROWNUM se počítá ještě před zpracováním ORDER BY). SYSDATE nemá v PostgreSQL přímý ekvivalent, místo něj lze využít NOW() s výchozí časovou zónou.
Lukáš Jelínek
PostgreSQL Backup Strategies
Magnus Hagander
Při nasazení databáze je jednou z důležitých věcí vymyslet strategii zálohování – zjednodušeně jak budete databázi zálohovat, kam, jak často, jak dlouho zálohy uchovávat a jak data v případě potřeby obnovit. Magnus Hagander hned na začátku zdůraznil, že replikace nebo clustering není ekvivalent zálohy – jistě, chrání to vaše data před vnějším zásahem, ale co když si data smažete vlastní aplikací a zjistíte to, až když budou zreplikovaná?
Existují dva základní způsoby zálohování databáze, buďto je to záloha logického charakteru, ze které máme většinou soubor plný SQL příkazů, nebo je záloha charakteru fyzického, např. záloha celého souborového systému.
Nástrojem pro logickou zálohu je například pg_dump, který má své výhody i nevýhody. Výhodou je, že pokud máte data v jedné databázi, tímto nástrojem je vždy dostanete konzistentní. Nevýhodou je fakt, že celá akce se děje pouze v jednom vlákně a trvá dlouho, ale také úzké hrdlo v podobě I/O. Magnus doporučil používat vždy místo výchozího plaintextu custom format, který je binární (a tudíž menší), komprimovaný (a tudíž ještě menší) a má vlastní index (takže se v něm rychleji zorientujete, pokud je gigantický). Navíc čím větší kompresi použijete, tím se proces zpomalí a nevytěžujete tolik disk. Zde je dobré zdůraznit, že rychlost provedení zálohy není důležitá (ve srovnání s rychlostí obnovení dat). Tento nástroj také umí zálohovat jen celou databázi najednou, což může být nevýhoda, ale pokud chcete mít data konzistentní, stejně to tak musíte dělat. Pokud chcete zálohovat i uživatele, skupiny a tablespacy, určitě nezapomeňte použít pg_dumpall.
 Magnus Hagander
Magnus Hagander
Pro obnovení pak použijete nástroj pg_restore, který už umí obnovit buď celou databázi, nebo jen některé její části. Můžete se rozhodnout, jestli chcete použít parametr -1, který zajistí, že se celé obnovení provede v jedné transakci, a pokud dojde k nějakému problému, nezůstane vám v databázi jen nekonzistentní půlka dat; nebo jestli použijete parametr -j, který využije víc session pro více tabulek. Podle Magnuse je druhá varianta rychlejší. Pro rychlost je důležité před obnovením vypnout fsync a po obnovení ho nejen nezapomenout zapnout, ale také zapsat cache operačního systému, což se prý nejlépe provede restartováním serveru.
Pokud se rozhodnete pro zálohy na úrovni souborového systému, získáte určitě na rychlosti, všechno trvá znatelně méně času. Bohužel vaše zálohy ale nebudou tolik přenositelné, protože budou záviset na architektuře procesoru, verzi PostgreSQL, ale také na kompilačních volbách (takže klidně na distribuci Linuxu, pokud se tam balíčky kompilují s jinou volbou). Je poměrně jasné, že se zálohuje a obnovuje buď všechno, nebo nic, na úrovni snímku disku si těžko zvolíte konkrétní tabulku. Offline zálohy fungují velmi dobře, ale bohužel musíte provést krátkou odstávku. Pokud provádíte zálohy online, ideální je mít všechno včetně WALL na jednom disku (což ale nemusí být ideální například pro výkon). Nikdy totiž nejste schopni udělat snapshot více disků přesně ve stejný okamžik a může tak dojít k inkonzistenci.
Další možností je zálohovat pomocí transakčního logu – musíte do něj ale psát všechno, co se s daty děje. Obnova dat tímto způsobem ale trvá dlouho, protože se v databázi vytvářejí a zase mažou data, která tam už nepotřebujete, v podstatě se znovu provede všechno od počátku existence databáze, což může být také klidně naprosto nereálné uchovávat. Proto je dobré čas od času provést pg_basebackup, který použije replikaci k vytvoření kompletní zálohy.
Ideálním řešením je třeba jednou za měsíc dělat basebackup, ale transakční log zálohovat průběžně. Hlavně nezapomeňte na pravidelné testování záloh, často se stává, že sice zálohujete, ale později zjistíte, že nejste schopni data obnovit.
Miroslav Hrončok
Debugging complex SQL queries with writable CTEs
Gianni Ciolli
Zkoušeli jste někdy vytvářet složitý dotaz obsahující vícenásobné vnoření a „nejlépe“ ještě několik spojení? Pokud ano, tak asi víte, že pokud se v takovém dotazu objeví chyba, může být velmi obtížné ji najít. Především je problém zjistit, zda je chyba v některé vnořené části (a v případě vícenásobného vnoření na které úrovni) nebo až v hlavním dotazu.
Gianni Ciolli si připravil přednášku o tom, jak lze při ladění takových dotazů využít Common Table Expressions (CTE), někdy označované jako „WITH dotazy“ (podle použitého klíčového slova). Jedná se v podstatě o dočasné tabulky pro výsledky poddotazů, jejichž obecnější podoba (umožňující použití nejen pro SELECT, ale i pro INSERT/UPDATE/DELETE), navíc s možností zápisu, se objevila v PostgreSQL verze 9.1. Základní podoba je v systému od verze 8.4.
 Gianni Ciolli
Gianni Ciolli
Pokud se někde používá složitější dotaz, který je třeba odladit, v prvním kroku je třeba ho přepsat do podoby využívající CTE. Následně se do CTE přidá logování, resp. u starších verzí (kde možnost přímého zápisu není) se přidají funkce, které logování umožňují. Tak si lze prohlédnout, jaká data vycházejí z poddotazů a zda odpovídají tomu, jak mají vypadat.
Metoda má ovšem určitá omezení. Například je problém v tom, že se zapisovací CTE vykonávají pouze jednou a nelze tedy sledovat rekurzivní dotazy. Dále nelze tuto metodu používat v případech, kdy se vyskytují kruhové reference v rekurzivních dotazech. Určitá úskalí přináší také samotný přepis dotazu, kdy může dojít k chybě – například v tom, že přepsaný dotaz nedělá totéž jako ten původní.
Lukáš Jelínek
Limiting PostgreSQL resource consumption using the Linux kernel
Hans-Jürgen Schönig
Běží-li s PostgreSQL na stejném stroji i další programy, může být aktuální otázkou, jak zajistit, aby databázový server – například současným prováděním většího počtu náročných dotazů – neohrozil běh ostatních programů. Odpověď na tuto otázku se liší podle operačního systému. Na GNU/Linuxu lze využít možnosti poskytované linuxovým jádrem, jak ukázal Hans-Jürgen Schönig.
Již dlouho Linux disponuje mechanismem ulimit na nastavování limitů na různé prostředky (různé druhy paměti, čas procesoru, počet otevřených souborů apod.). Ten ale umožňuje jen nastavování globálně pro určitého uživatele či skupinu. V tomto případě se ale hodí jemnější rozlišení – to nabízí technologie cgroups (control groups), která je k dispozici od jádra veze 2.6.24.
Technologie cgroups umožňuje vytvářet skupiny (i hierarchicky, tedy s možností každou skupinu členit na další skupiny) a nastavovat jim, jaké prostředky mohou využívat. Například lze určit procesory (jádra), na kterých procesy z dané skupiny poběží, kolik paměti smějí využívat, jakou šířku I/O pásma atd.
Umísťovat procesy do skupin lze buď ručně pomocí programu cgclassify, běžně je ale lepší to dělat automaticky s využitím služby (démona) cgred. Lze nastavit pravidla podle uživatelů, příkazů (programů) a subsystémů. Proces lze do skupiny zařadit již hned při spuštění, a to spuštěním pomocí příkazu cgexec. Je výhodné při spouštění i ručním umísťování používat parametr --sticky, který zajistí, že i potomci tohoto procesu poběží v dané skupině.
V případě PostgreSQL lze využít jak spouštění pomocí cgexec, tak umísťování službou cgred. Následně je možné sledovat, jak daná skupina prostředky využívá. cgroups má souborové rozhraní připojené na adresář /cgroup, kde jsou podadresáře jednotlivých skupin a v nich pak soubory s údaji o prostředcích. Například v memory.stat je statistika využití paměti. Možnost používání cgroups samozřejmě není omezena jen na PostgreSQL, nýbrž lze opačně chránit databázový systém proti „nenažranosti“ jiných procesů.
Lukáš Jelínek
Large Scale MySQL Migration to PostgreSQL
Dimitri Fontaine
Další přednáška o tom, jak u konkrétního případu přecházeli z MySQL na PostgreSQL. Tentokrát se jednalo o webovou službu Fotolog, kterou dříve používalo 32 milionů uživatelů, kteří nahráli miliardu fotek a komentářů – více než 6 TB uživatelského obsahu. Bohužel MySQL to neustála, a tak službu museli zastavit a poohlédnout se po jiném řešení. Dimitri Fontaine celý ekosystém převáděl na PostgreSQL a služba již opět běží. Původní řešení bylo prý tak hrozně navržené, že kromě změny databáze raději celý systém přepracovali od začátku.
 Dimitri Fontaine
Dimitri Fontaine
Pro přenos dat chtěli použít Foreign data wrapper, který by jim umožnil provést celkem jednoduchou konstrukci INSERT INTO new_table * FROM remote_mysql_table – bohužel nevýhodou tohoto řešení je rychlost, respektive spíše pomalost. Chtěli tedy použít CSV, ale jeho export z MySQL neescapuje oddělovače v datových buňkách, takže toto řešení bylo také k ničemu. Raději si tedy napsali vlastní jednoduchý mysql2csv klient a data nalili do PostgreSQL pomocí pgloaderu. použili ale mezivrstvu ve formě další PostgreSQL databáze, kde všechny buňky byly textové – původní MySQL totiž obsahovala hodnoty, které by u PostgreSQL neprošly (například datum 0000-00-00).
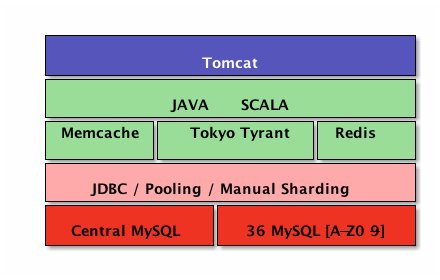 Architektura původního řešení
Architektura původního řešení
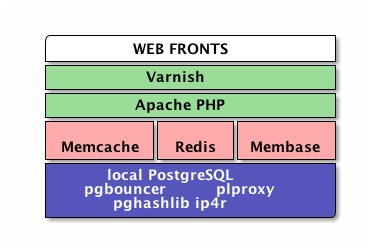 Architektura nového řešení
Architektura nového řešení
Jednou z hrůzných součástí původního řešení byly MySQL Java blobs uložené v tabulkách pomocí Google Protocol Buffers. Aby to celé mohli vůbec rozkódovat, použili v PostgreSQL pl/Java.
Miroslav Hrončok
PostgreSQL adoption at the tipping point
Ed Boyajian
V podstatě již závěrečnou keynote (před informacemi „komunitního charakteru“ a o samotné konferenci) byl stručný přehled toho, jaké pozice si systém PostgreSQL již dokázal vydobýt a jaká je vůbec situace v celé oblasti.
Především se ukazuje, že ve střednědobém horizontu bude velká poptávka po všech moderních systémech pro ukládání dat a po analytických nástrojích pro tato data. Platí to i pro relační databáze, mezi které PostgreSQL patří.
 Ed Boyajian
Ed Boyajian
Zajímavou informací je, že se o PostgreSQL zajímají hlavně velké firmy, a to často takové, které patří mezi leadery ve svých tržních sektorech. Bohužel jsme se ale nedočkali odhalení identity zmíněných největších firem, protože by jistě nebylo na škodu vědět (třeba jen čistě pro zajímavost), které to jsou.
Lukáš Jelínek