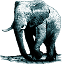
Tuto reportáž napsali dva autoři: Tomáš Crhonek a Miroslav Hrončok. Pro rozlišení autora textu jsou v úvodu každého bloku o přednášce uvedeny jeho iniciály. Autorem fotografií je Tomáš Crhonek. LinuxEXPRES je mediálním partnerem P2D2.
Magnus Hagander: Data-driven cache invalidation
MH První odpolední přednáška nesla název, který mě příliš nelákal, nedokázal jsem si totiž představit, o čem bude Magnus Hagander vlastně mluvit. O to mileji jsem byl překvapen, když se přednáška ukázala být rozhodně jednou z nejlepších. Magnus nastínil vzorovou situaci: Založíte si blog, a přestože jste to nečekali, za chvíli má ohromnou návštěvnost – milion zobrazení stránky za minutu – a to pochopitelně server a databáze neutáhne. Tehdy přijde na řadu cache.
 Magnus Hagander
Magnus Hagander
Magnus z mírně předpřipravených komponent sestavil přímo na přednášce jednoduchý blog, který dokázal zobrazit všechny příspěvky pod sebou, nebo každý příspěvek zvlášť. K ukládání dat použil pochopitelně PostgreSQL a k naprogramování blogu použil django. Do patičky generovaných stránek umístil datum a čas, abychom poznali, jestli se stránka generuje, nebo načítá z cache. Magnus nejdříve předvedl variantu bez cache, kde se pochopitelně čas měnil s každým načtením stránky. V tomto režimu Magnus přidal i blogpost, který se hned zobrazil.
V dalším kroku přidal jako mezivrstvu cachovací server Varnish, který nastavil tak, aby vše (kromě administračního rozhraní) cachoval po dobu jedné hodiny. Při prvním načtení stránky se čas v patičce zafixoval a nové načítání stránky čas neměnilo, protože se stále používala verze z cache. Pak Magnus upravil titulek blogpostu, což se, dle očekávání většiny účastníků, na blogu neprojevilo, protože vše bylo stále v cache. Mohli bychom sice hodinu počkat, ale to bychom v čase vyhrazeném na přednášku nestihli.
S Magnusem Haganderem, členem PostgreSQL Core Teamu a prezidentem PostgreSQL Europe, máme připravený rozhovor.
Zde Magnus popisoval, že je nutné nějakým mechanismem zajistit, aby se při změně obsahu uložila do cache nová verze stránky. To můžete udělat v aplikaci (v tomto případě v blogu), ale nese to s sebou nevýhodu: pokud k databázi přistoupíte přímo nebo přes nějakou jinou aplikaci, změna se neprojeví. Proto se vyplatí řešit vše už na úrovni databáze. V PostgreSQL lze vytvořit trigger, který zajistí, že kdykoli dojde ke změně nějakého blogpostu nebo k přidání dalšího, patřičné stránky se v cache smažou.
 Vše se dá řešit na úrovni databáze
Vše se dá řešit na úrovni databáze
Pokud máte několik cache serverů, třeba v různých částech světa, můžete v triggeru pouze přidávat požadavky na smazání dat z cache do fronty, kterou realizujete pomocí PgQ. Na každém cache serveru pak budete mít komponentu, která bude požadavky na smazání obsluhovat.
Tomáš Vondra: SSD, fsync, úroveň WAL logu a jejich vliv na výkon
TC Tomáš připomenul, že vývojář by si měl umět klást správné otázky a v úvodu přednášky několik z nich položil. Vývojář by měl mít základní povědomost o způsobu uložení dat a v Postgresu bychom si měli klást otázky jako například tyto: Která data (datové soubory, indexy, WAL) umístit na samostatný disk a jaký výkon to přinese? Pokud máme k disposici SSD, na která data jej použít? Jaká je nejrychlejší (a stále bezpečná) metoda synchronizace?
Po těchto otázkách následovala technická data o SSD a HDD a představení jednotky výkon/cena/GB (klasický poměr výkon/cena vztažený na velikost média). HDD jsou velké a relativně pomalé, ale zase velmi levné, SSD jsou malé a drahé, ale velmi rychlé, alespoň v některých situacích, v jiných jsou jen o málo rychlejší než klasické rotující disky, což jejich cenu neospravedlní.
Po tomto úvodu o způsobu ukládání dat, jednotkách použitých v testu a představení hardwaru následoval popis dvou základních testů, a to OLTP (TPC-B, pgbench, „malé pseudonáhodné dotazy“) a DWH (TPC-H, „dotazy na veliký objem dat“). A situace se rázem zkomplikovala. Alespoň jeden výsledek mohu prozradit: v testu OLTP excelovaly SSD, zatímco v DWD naopak HDD. A ještě je důležité, zda jsou data a indexy umístěny na samostatných discích a jakého typu: čtyři kombinace dvou disků, dva testy, mnoho různých výsledků, a to ještě z pohledu čistého výkonu a potom z pohledu ceny za tento výkon.
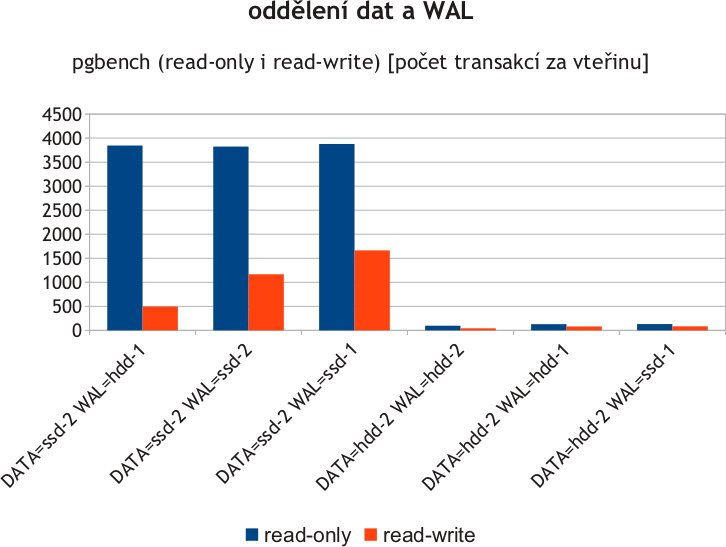 Srovnání různých uložení dat a WALu na SSD a HDD
Srovnání různých uložení dat a WALu na SSD a HDD
Dalším testem, opět v mnoha různých kombinacích, byl test výkonu databáze při umístění dat a WAL na dvě různá zařízení, opět dvojího typu a opět s přihlédnutím na jejich cenu. Posledním testem byla metoda synchronizace (fsync) WAL logu a jeho vliv na rychlost databáze na různých zařízeních.
Hodnotná přednáška, pro mě jakožto technika, přinesla velmi mnoho cenných výsledků a chtěl bych za to Tomášovi poděkovat. Mohu vám jen doporučit projít si Tomášovy slajdy z přednášky, další testy má na svém webu, vaší pozornosti doporučuji test výkonu Postgresu na mnoha různých systémech souborů v různých konfiguracích.
Tomáš Pospíšil: Indexování XML dat v PostgreSQL (GSoC 2011)
MH Tomáš Pospíšil v rámci Google Summer of Code doprogramoval do PostgreSQL několik věcí, které napomohly k uložení XML dokumentů do databáze. Již předtím to bylo sice možné, ale chyběly některé zásadní funkce, především indexace a validace.
 XML v PostgreSQL
XML v PostgreSQL
Tomáš posluchače nejdříve seznámil se situací v PostgreSQL předtím, než potřebnou funkcionalitu doprogramoval, poté se pochlubil nějakými statistikami, kterým jsem ale bohužel opravdu nerozuměl :(
Nakonec Tomáš vysvětlil projekt Google Summer of Code. Pokud jej neznáte, vězte, že je to v zásadě jednoduché. Student pracuje přes léto na konkrétním vylepšení nějakého open-source projektu a za to dostane zaplaceno od Googlu. Navíc má z daného projektu k dispozici mentora. Není to však příliš snadné, projekty, konkrétní úkoly a studenti, to vše prochází přísnou kontrolou a zájemců je mnoho.
Pavel Stěhule: Column-stores (MonetDB, LucidDB...)
TC Zatímco Tomáš ve své přednášce hovořil o ukládání dat v podobě datových souborů, indexů a WAL, Pavel šel ještě „o patro níže“. Ukázal, jakým způsobem většina současných relačních databází ukládá řádky do stránek, jaké to má výhody a nevýhody pro určitá nasazení. Pokud aplikace potřebuje vytvářet velmi široké tabulky (typické pro OLAP) a poté zpracovávat pouze data z několika málo sloupců, databázový server musí z disku načíst celou stránku, zpracovat celé řádky, ze kterých potřebuje pouze malé procento záznamů. Většina dat se tak pro tento typ zpracování čte zbytečně. Proto byl vymyšlen způsob ukládání po sloupcích, databáze tak může velice efektivně sekvenčně číst tabulku po vybraných sloupcích, což je velmi rychlé.
V databázovém světě jako takovém se od roku 2000 děje hodně věcí, částí přednášky bylo velmi poučné zamyšlení nad úspěchem NoSQL databází a to, který relační databázový produkt za to „může“. Následoval krátký úvod do různých tříd databázových systémů. Hodně užitečný byl také historický exkurz do sedmdesátých let (minulého století) a připomenutí původu dnešních relačních databází (parser, optimalizátor plánu, pipeline exekutor nad stránkami s řádky).
 Návštěvníci konference
Návštěvníci konference
Na přednášce se diváci dozvěděli o dvou produktech z řady sloupcových databází: MonetDB a LucidDB (obě open-source, i když s Monetem je to nahnuté), a mimo jiné také o tom, že Pavel nemá rád Javu, což část publika ocenila potleskem. Oba produkty jsou SQL databáze, podporující ACID, a jsou optimalizované pro OLAP a star schéma a pro rychlé nahrání většího množství dat (s nevýhodou velmi pomalých změn jednotlivých řádků, tyto produkty by se měly používat pro analytické dotazy, kde se z tabulek pouze čte).
Hodně zajímavé a pro příznivce PostgreSQL (což je stejně jako MySQL databáze s klasickými stránkami obsahujícími řádky) jistě velmi potěšitelné byly testy výkonu LucidDB, MonetDB, PostgreSQL a MySQL, kde první dvě jsou optimalizované na tento typ úloh (OLAP), zatímco druhé dvě nikoliv. Sloupcové databáze Monet a Lucid nepřekvapivě vyhrály (14 a 23 sekund), následovány Postgresem (26 sekund) a někde vzadu MySQL (4 minuty). Asi nejen já jsem se v této chvíli zamyslel nad nutností vývoje dalších produktů, když už tu je jeden, který tyto úlohy (navzdory klasické architektuře) dobře zvládá. Navíc a bohužel, Monet se uzavřel do komerčního světa.
 Výsledek testu
Výsledek testu
Lightning talks
MH Na úplný konec programu byly zařazeny takzvané lightning talks. Jedná se o krátké prezentace, které může přednést libovolný účastník konference. Ve čtvrtečním případě měly prezentace maximálně sedm minut. Osobně jsem byl na tuto část programu velmi zvědavý, protože minulý ročník byla na konec programu zařazena odlehčující přednáška SQL Puzzlers, která mě hodně pobavila. Lightning talks mě ale jako celek zklamaly. Ne že by jednotliví lidé nebo jejich přednášky nestáli za to, ale celá akce měla příliš malou účast a kromě lidí, kteří již prezentovali na konferenci něco jiného, promluvil pouze jeden člověk navíc.
Jako první vystoupil Magnus Hagander, který mluvil o tom, že je strašně jednoduché hashovat hesla v databázi, a přesto to skoro nikdo nedělá. Nejdříve ukázal nějaké titulky z novin, aby své tvrzení dokázal (např. o deseti tisících uniklých heslech z Hotmailu). Magnus ve svých sedmi minutách také prakticky předvedl, jak vše dělat v PostgreSQL.
Následoval Vašek Frolík, který předvedl PostgreSQL plugin pro Eclipse. Dříve existoval takový plugin pro Oracle, ale nyní jej v Ostravě uzpůsobili i pro PostgreSQL.
 PostgreSQL plugin pro Eclipse
PostgreSQL plugin pro Eclipse
Předposlední krátkou řeč měl Simon Riggs, který popisoval validaci stránek na základě kontrolního součtu. V některé z příštích verzí Postgresu (pravděpodobně 9.2) bude možné mít v hlavičce stránky místo čísla verze kontrolní součet. Půjde však určitě o volitelnou variantu.
Lightning talks zakončil Tomáš Vondra, který předvedl, jak použít český fulltext a sdílené slovníky. Problém je v tom, že algoritmické převedení slov na první pády a infinitivy nefunguje např. u češtiny a slovenštiny nebo dalších slovanských jazyků, takže se musí použít slovník. Slovník se ale načítá do paměti znovu a znovu při každém připojení k databázi, což není dobré. Při dvaceti pěti připojeních a dvou slovnících (českém a ceskem bez hacku a carek) se dostanete na 500 MB v paměti, což může znamenat například na VPS dost veliký problém. Proto Tomáš vytvořil komponentu shared_ispell, která umožňuje používat společný slovník pro všechna spojení.
Na webu konference můžete najít slajdy z jednotlivých přednášek.