
Scaling, Autoscaling, Scale-up, Scale-out
Na začátek krátké vysvětlení základních pojmů. Škálování, tedy scaling, je navyšování výpočetních prostředků aplikací nebo paralelizace výpočetních jednotek (v zásadě stále „přidávání výkonu“). Pokud se má škálování odehrávat dynamicky a automaticky dle aktuální potřeby, jde o autoscaling. Autoscaling se rozhoduje podle různých metodik – load serveru, objem datových toků, počet requestů, latence requestu, množství chyb, které vrací aplikace z důvodu nemožnosti request odbavit.
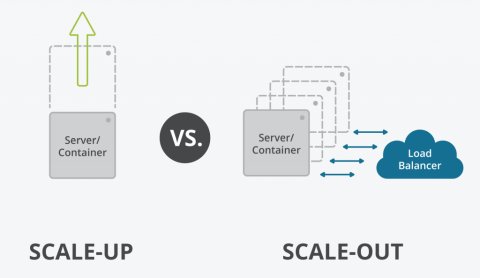
Scale-up je model vertikálního škálování, což je nejtypičtější způsob škálování, na který aplikace nemusí být nijak zvlášť připravená. V zásadě jde o navyšování výkonu serveru. Tento model má tu nevýhodu, že často nejde provádět za běhu, jeho možnosti nejsou neomezené a je také možné, že některé aplikace již nedokáží takový výkon v rámci jednoho serveru utilizovat a bottleneck je poté někde „uvnitř“ aplikace.
Scale-out je škálování formou paralelizace výpočetních jednotek – přidávání serverů, virtuálních serverů, kontejnerů za load balancerem. Na tento způsob škálování musí být aplikace připravena, výhodou oproti tomu je větší rozsah možností škálování.
Scaling killer 1 – relační databáze
Nejtypičtějším zabijákem škálování jsou relační databáze (MySQL, PostgreSQL, …), což jsou produkty, které vznikly před více než 20 lety v době, kdy pojem škálování v tomto pojetí prakticky neexistoval. Podpora pro clusterování byla různě dolepována až následně, popř. řešena jinými produkty třetích stran. Nejdříve je tedy potřeba se zamyslet, zda vůbec relační databázi ve vaší aplikaci potřebujete používat.
Například e-shopy s objednávkami, fakturami, uživateli apod., vyžadující ukládání dat do něčeho, co splňuje vlastnosti ACID, se bez relační databáze neobejdou. Zamyslete se ale nad tím, zda není možné v případě vašeho use case použít některou z noSQL databází, které byly většinou už od začátku koncipovány jako clusterovatelné, tedy škálovatelné. Stále se ještě setkávám s tím, že někdo do relační databáze ukládá logy, sessions a další, což jsou všechno věci, na které existují specializované nástroje (pro sessions například in-memory noSQL databáze redis, logy např. syslog apod.). Naprosto nejhorší z pohledu škálování a relačních databází jsou zápisové operace, kde je reálná možnost škálování pouze vertikálně.
U selectů je ještě možné provoz rozdělit. Například Amazon RDS umožňuje přidávat read-only replicy, naše služba Zerops bude podporovat Galera cluster jako službu a bude zajišťovat výrazně větší pohodlí z pohledu škálování. Nicméně princip nemožnosti škálovat zápisové operace horizontálně platí v obou případech. Měli byste se tak vyhnout například využívání relační databáze k ukládání různých statistik, číselných řad a dalších (přesně k tomuto účelu se hodí více noSQL databáze – mongo, ElasticSearch apod.).
Relační databázi z pohledu horizontálního škálování je třeba brát jako nutné zlo a operace, zejména zápisové, je potřeba maximálně omezit z pohledu náročnosti a intenzity.
Scaling killer 2 – sdílený filesystém
Moderní aplikace se bez sdíleného filesystému již obejdou, drtivá většina aplikací však stále ne. Aplikace předpokládá, že má v adresářové struktuře uloženy kromě aplikace i data – tedy obrázky, logy atd. Špatně napsané aplikace ukládají do adresářové struktury různé cache. Filesystém je další desítky let starou záležitostí, která již měla dávno zhynout. Pokud se nebavíme o aplikaci globálního rozsahu a nepracuje se s filesystémem nekoncepčně, nejde zas o takový problém, protože se na limity pravděpodobně nemusí nikdy narazit. Pokud se ale s FS pracuje nekoncepčně, hrozí zásadní problém, který žádné škálování ničeho většinou nevyřeší, navíc jde často o problémy, které o sobě nedají vědět dříve, než se reálně projeví.
Typicky jde o:
- špatnou adresářovou strukturu – ukládání statisíců (nebo mnohem více) objektů (souborů, adresářů) v jednom adresáři. Otevření takového adresáře pak mnohdy trvá spoustu minut.
- velké množství operací s filesystémem – zbytečné operace při každém přístupu uživatele nad mnoha soubory a generování lstat operací (typicky jsou to funkce v PHPku na ověření existence obrázku při každém přístupu apod. nebo absence souborové cache, kdy aplikace při každém přístupu generuje přístup na filesystém)
- ukládání cache do adresářové struktury – pokud ukládání do adresářové struktury, tak určitě ne do sdíleného filesystému mezi více servery, ale do ramdisku na lokálním serveru. Na sdíleném filesystému krok přetížení hrozí čekáním na soubor cache vlivem zámku souboru, který zrovna vytvořil jiný server, který s cache pracuje.
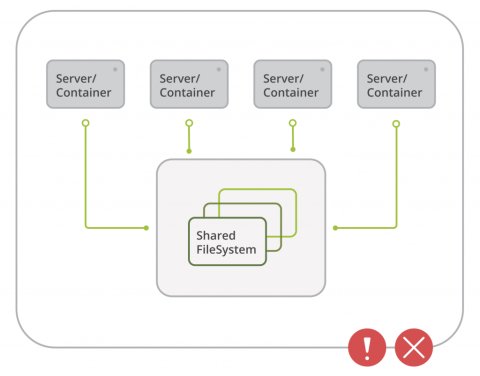
Jak si poradit bez sdíleného filesystému? Je nutné dodržovat základní filozofii rozdělení aplikace a dat. Aplikace by měla být provozuschopná i v read-only režimu (poté může běžet klidně v RAMce) a neměla by vytvářet žádné lokální soubory (případný temp adresář pro dočasná nedůležitá data se řeší jako jeden zapisovatelný adresář umístění také na RAMdisku). S daty se pracuje tak, že se použijí nástroje, které jsou k tomu určené – například syslog pro vzdálené logování, object storage pro práci s obrázky a dalšími uživatelskými daty, no a samozřejmě databáze.
Výše uvedení zabijáci škálování jsou nejčastější příčinou zhoršených možností škálování infrastruktury, se kterými se 11 let setkáváme u velkých internetových projektů.

Damir Špoljarič
Autor článku je CEO a zakladatel společnosti VSHosting, která provozuje datacentrum ServerPark a má mnoho zkušeností s provozem náročných databázových clusterů. Nabízí také službu Zerops, což je cloudová platforma pro vývoj moderních škálovatelných aplikací.