Specializuji se na Elasticsearch a jsem fanouškem DevOps. Nabízím konzultace a školení Elasticsearch - pokud jej chcete poznat důkladněji, zjistit, zda se hodí pro váš projekt, nebo uspořádat školení ve vaší firmě, neváhejte se mi ozvat.
V tuto chvíli umíme vytvořit fulltextové vyhledávání v češtině nad názvem produktu. V praxi je však situace zpravidla složitější - vyhledávat chceme ve více polích dokumentu, v každém pak s jinou logikou. V této kapitole si tak předvedeme návrh a implementaci pokročilejšího fulltextového vyhledávání použitelného v e-shopu.
Požadavky na vyhledávání
Budeme vytvářet vyhledávání, které odpovídá následujícím požadavkům:
- Hledá se primárně v názvu produktu, nehledě na tvarosloví
- Dále se hledá v názvu produktu s ohledem na české tvarosloví
- Hledá se i v popisku produktu, avšak s nejnižší prioritou
Data, v kterých se vyhledává
Vyhledávat se bude v následujících produktech:
Produkt č. 1:
- Název: Jablka golden 1 ks
- Popisek: Veškeré ovoce je prémiové kvality
Produkt č. 2:
- Název: Jablko idared
- Popisek: Kvalitní a čerstvé ovoce
Produkt č. 3:
- Název: Müsli
- Popisek: Křupavé müsli s jablky
Vhledávání výrazy
Po uložení produktů do Elasticsearch budeme vyhledávání ladit pomocí následujících výrazů:
jablka idaredjablkaidared
Pro výraz jablka idared budeme jako první očekávat produkt Jablko idared, protože se v názvu shodují obě slova. Následně budeme očekávat Jablka golden 1 ks, protože oba produkty mají slovo jablko v názvu. Jako poslední budeme očekávat produkt Müsli, který má slovo jablko pouze v popisku.
Pro výraz jablka budeme očekávat jako první produkt Jablka golden 1 ks a jako druhý Jablko idared. Sice mají slovo jablko v názvu shodně oba produkty, ten první jej má však ve stejném tvaru, jako je hledaný výraz. Jako třetí by se měl ve výsledcích objevit produkt Müsli, který slovo jablko obsahuje pouze v popisku.
Nakonec pro výraz idared očekáváme jako první nalezený produkt Jablko idared. Měl by to být zároveň jediný nalezený produkt, ostatní tento výraz neobsahují ani v názvu, ani v popisku.
Vytvoření indexu a uložení dat
Pro vyhledávání vytvoříme index s jedním typem, přičemž každý dokument bude tvořen poli title a description. Již při vytváření indexu musíme přemýšlet, jak se v jednotlivých polích bude vyhledávat.
Začneme popiskem, ve kterém se bude vyhledávat v českém jazyce, nehledě na tvarosloví, velikost písmen, nebo diakritiku. Vzhledem k tomu, že půjde zpravidla o delší text, je vhodné vypustit slova nevýznamná pro vyhledávání.
V názvu produktu pak budeme chtít vyhledávat dvěma způsoby. Jednak budeme vyhledávat obdobně jako v případě popisku (jen nebude třeba vypouštět žádná slova - vzhledem k délce názvů produktů mohou mít významnou informační hodnotu). V názvech produktů však budeme chtít vyhledávat také slova, která přesně odpovídají zadanému výrazu a ta pak ve výsledcích vyhledávání zobrazit výše. Musíme tedy toto pole uložit i ve tvaru nepřevedeném na základní tvar.
Nastavení indexu a mapování
Z těchto požadavků vyplývá, jaké analyzéry bude potřeba nakonfigurovat. Budou celkem tři, přičemž všechny budou dělit slova mezerami, text převádět na malá písmena a odstraňovat diakritiku. V tom ostatním se však budou lišit: Analyzér pro popisek musí vypouštět stop slova a převádět je na základní tvar. První analyzér pro titulek je bude jen převádět na základní tvar, druhý analyzér už ale nebude vypouštět stop slova, ani slova převádět na základní tvar. Kompletní nastavení indexu (včetně mappingu) tak bude vypadat následovně:
PUT products
{
"settings": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis": {
"analyzer": {
"czech_hunspell_stopwords": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"min_length",
"czech_stop",
"czech_hunspell",
"lowercase",
"czech_stop",
"icu_folding",
"unique_on_same_position"
]
},
"czech_hunspell": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"czech_hunspell",
"lowercase",
"icu_folding",
"unique_on_same_position"
]
},
"czech_lowercase": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"icu_folding"
]
}
},
"filter": {
"czech_hunspell": {
"type": "hunspell",
"locale": "cs_CZ"
},
"czech_stop": {
"type": "stop",
"stopwords": [
"že",
"_czech_"
]
},
"unique_on_same_position": {
"type": "unique",
"only_on_same_position": true
},
"min_length": {
"type": "length",
"min": 2
}
}
}
},
"mappings": {
"products": {
"properties": {
"title": {
"type": "keyword",
"fields": {
"czech_hunspell": {
"type": "text",
"analyzer": "czech_hunspell"
},
"czech_lowercase": {
"type": "text",
"analyzer": "czech_lowercase"
}
}
},
"description": {
"type": "text",
"analyzer": "czech_hunspell_stopwords"
}
}
}
}
}
Nejsložitější je zde analyzér czech_hunspell_stopwords, ve kterém nejprve odstraňujeme krátká a nevýznamná slova - následující analýza je totiž výpočetně náročná a je tak vhodné před ní co nejvíce slov odfiltrovat. Veškeré nastavení filtrů by však mělo být známé na základě předchozí kapitoly tohoto seriálu.
Nové je ale nastavení pro pole title, které je ukládáno dvěma způsoby - pomocí analyzérů czech_hunspell a czech_lowercase. Při vyhledávání se k nim bude přistupovat jako title.czech_hunspell a title.czech_lowercase.
Do vytvořeného indexu můžeme uložit produkty. Abychom nemuseli postupně vykonávat request pro každá dokument, je možné využít Bulk API a data tak do Elasticsearch uložit naráz:
POST _bulk
{"index": {"_index": "products", "_type": "products", "_id": "1"}}
{"title": "Jablka golden 1 ks", "description": "Veškeré ovoce je prémiové kvality"}
{"index": {"_index": "products", "_type": "products", "_id": "2"}}
{"title": "Jablko idared", "description": "Kvalitní a čerstvé ovoce"}
{"index": {"_index": "products", "_type": "products", "_id": "3"}}
{"title": "Müsli", "description": "Křupavé müsli s jablky"}
Vyhledávání
Nyní bude třeba vytvořit vyhledávací dotaz. Vyhledávat se bude ve více polích, nevystačíme si tedy s klasickým vyhledáváním pomocí match. Možným řešením by bylo použít těchto dotazů více a ty mít v rámci bool query, nicméně toto řešení je poměrně těžkopádné. Jako ideální pro tento případ se jeví použití multi_match query:
GET products/_search
{
"query": {
"multi_match": {
"query": "jablko",
"fields": [
"title.czech_lowercase^2",
"title.czech_hunspell",
"description^0.3"
]
}
}
}
Dotaz multi_match se od match liší tím, že mu lze předat seznam více polí, v nichž má vyhledávat. Vyhledává se tedy v titulku, který je indexován dvěma způsoby (title.czech_lowercase a title.czech_hunspell) i v popisku (description).
Vyhledávání navíc zohledňuje i váhu jednotlivých polí při vyhledávání přidáním ^2 resp. ^0.3 za název pole. Zde je v poli title.czech_lowercase vyhledáváno s nejvyšší prioritou (skóre při vyhledávání v tomto poli je násobeno dvěma) a v poli description naopak s prioritou výrazně nižší (0.3 krát než u title.czech_hunspell).
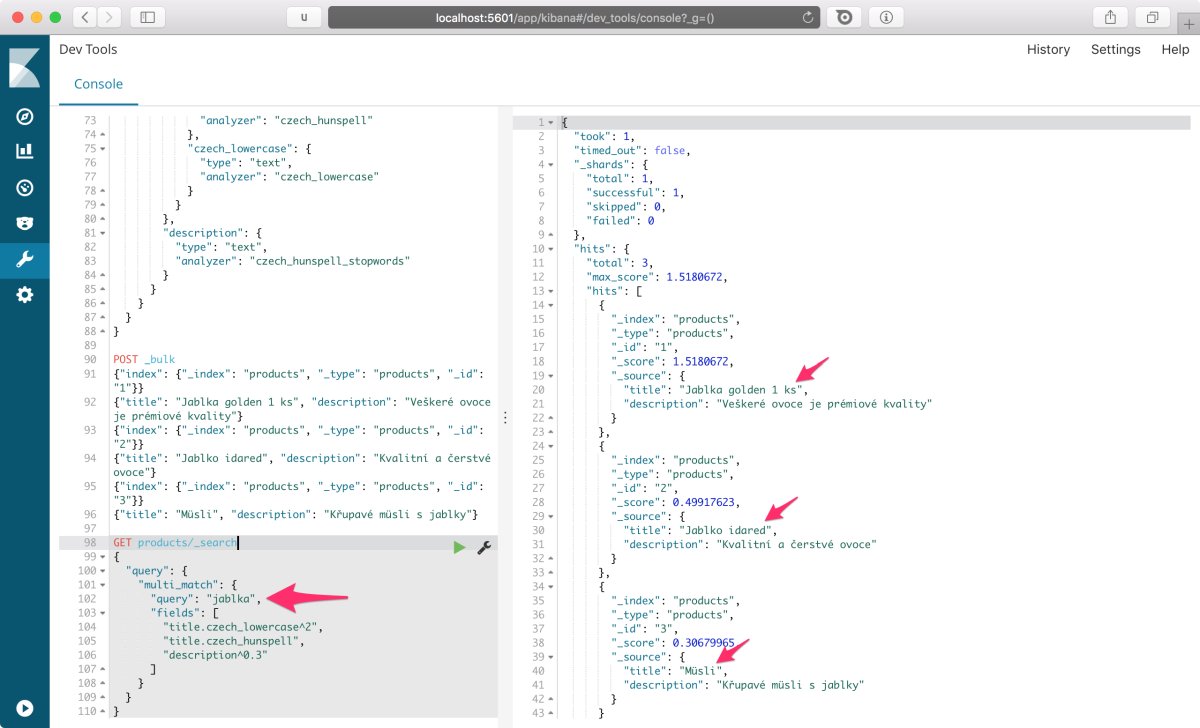
Výsledné vyhledávání můžeme otestovat na výrazech definovaných v úvodu, kdy zjistíme, že implementované vyhledávání plně odpovídá požadavkům. Například při vyhledávání výrazu jablka jsou správně nalezeny všechny produkty v pořadí Jablka golden 1 ks (slovo jablka v titulku ve shodném pádu), Jablko idared (slovo jablka v titulku v jiném pádu), Müsli (slovo jablka v popisku):
Další tipy pro vyhledávání
Záleží na požadavcích na vyhledávání i na datech, v nichž se vyhledává, jak vhodně nastavit váhy mezi jednotlivými poli. Pro úplnost ještě doplním, že ve výchozím stavu je způsob vyhledávání nastaven na best_fields, kdy se bere v potaz nejlepší skóre při vyhledávání v jednotlivých polích. K dispozici je ale i most_fields, kdy jsou získána skóre ve všech polích a ta jsou následně pronásobena. Dostupných konfigurací je samozřejmě mnohem více, to už je ale nad rámec tohoto seriálu.
Další možností, jak zlepšit vyhledávání může být použití algoritmického stemmeru jako doplňku k stemmeru slovníkovému. Tento stemmer může pomoci vykrýt případy, kdy slovník nezná některá indexovaná slova. Dalším zlepšením by mohlo být přidání token filtru Shingle, který vygeneruje všechny možné kombinace sousedních slov a pomůže tak zpřesnit vyhledávání frází. Samostatnou kapitolou je pak neúplné vyhledávání, ať už se jedná o překlepy, nebo našeptávání.