Specializuji se na Elasticsearch a jsem fanouškem DevOps. Nabízím konzultace a školení Elasticsearch - pokud jej chcete poznat důkladněji, zjistit, zda se hodí pro váš projekt, nebo uspořádat školení ve vaší firmě, neváhejte se mi ozvat.
V zásadě jsou možnosti jak zprovoznit Elasticsearch:
- Stažení ZIP archivů
- Použít Docker
- MSI installer pro Windows
V tuto chvíli se bavíme o zprovoznění lokálního vývojového prostředí, instalaci v produkčním prostředí se budeme věnovat až v závěru tohoto seriálu. Existují také další způsoby instalace, například pomocí deb nebo rpm balíčků. Cílem tohoto seriálu však není poskytnout všechny možné případy, od toho je k dispozici oficiální dokumentace.
Vzhledem k tomu, že je Elasticsearch psaný v Javě, stačí stáhnout připravené ZIP archivy a v nich spustit patřičné soubory. V této kapitole popisuji veškeré nutné kroky, na závěr jsou však k dispozici v jediném BASH skriptu. Pokud máte nainstalovaný Docker, je jeho použití pravděpodobně nejjednodušší způsob, jak Elasticsearch a další nástroje spustit. Pro Windows je pak připraven MSI instalátor s grafickým průvodcem.
Prerekvizity
Pokud ještě nemáte stažený repozitář z GitHubu k tomuto tutoriálu, nyní je ta pravá chvíle.
# stažení repozitáře
git clone git@github com:ludekvesely/elasticsearch-tutorial.git
# přepnutí se do stažené složky
cd elasticsearch-tutorial
com:ludekvesely/elasticsearch-tutorial.git
# přepnutí se do stažené složky
cd elasticsearch-tutorial
Tato složka obsahuje jak instalační skripty pro stažení ZIP archivu, tak soubory pro vytvoření stacku v Dockeru. V tomto návodu začneme nejprve instalací pomocí jednotlivých příkazů - použití výsledného skriptu nebo Dockeru pak tuto práci jen automatizuje.
Instalace stažením ZIP archivů
Pro spuštění Elasticsearch je nutné mít korektně nainstalovanou Javu, doporučována je verze Oracle JDK 1.8.0 nebo vyšší. Stáhnout ji lze z webu Oracle. To, že máte nainstalovanou správnou verzi je možné ověřit následujícími příkazy:
java -version # java version "1.8.0_05" # Java(TM) SE Runtime Environment (build 1.8.0_05-b13) # Java HotSpot(TM) 64-Bit Server VM (build 25.5-b02, mixed mode) echo $JAVA_HOME # /Library/Java/JavaVirtualMachines/jdk1.8.0_05.jdk/Contents/Home
Pro instalaci z terminálu jsou navíc vyžadovány další konzolové nástroje: wget, unzip a tar. Ty můžete nainstalovat prostřednictvím vašeho balíčkovacího manažera (např. Homebrew v případě OS X, apt-get v případě Debian/Ubuntu). Pro dotazování se Elasticsearch z konzole lze použít nástroj curl.
Pro zachování konzistence a předejití možným nedorozuměním spouštějte všechny následující konzolové příkazy ve složce staženého repozitáře (elasticsearch-tutorial).
Je třeba také zmínit, že nové verze Elasticsearch a vlastně všech produktů firmy Elastic jsou vydávány poměrně často. Může se tak stát, že aktuální verze je o mnoho vydání novější. V tom případě zpravidla stačí upravit číslo verze (zde 6.2.3) ve skriptech za odpovídající verzi.
Stažení Elasticsearch
Z dostupných variant bude na všech operačních systémech funkční verze využívající stažení a následné rozbalení ZIP archivu. Pokračujte tedy na adresu www.elastic.co/downloads/elasticsearch a klikněte na možnost ZIP.
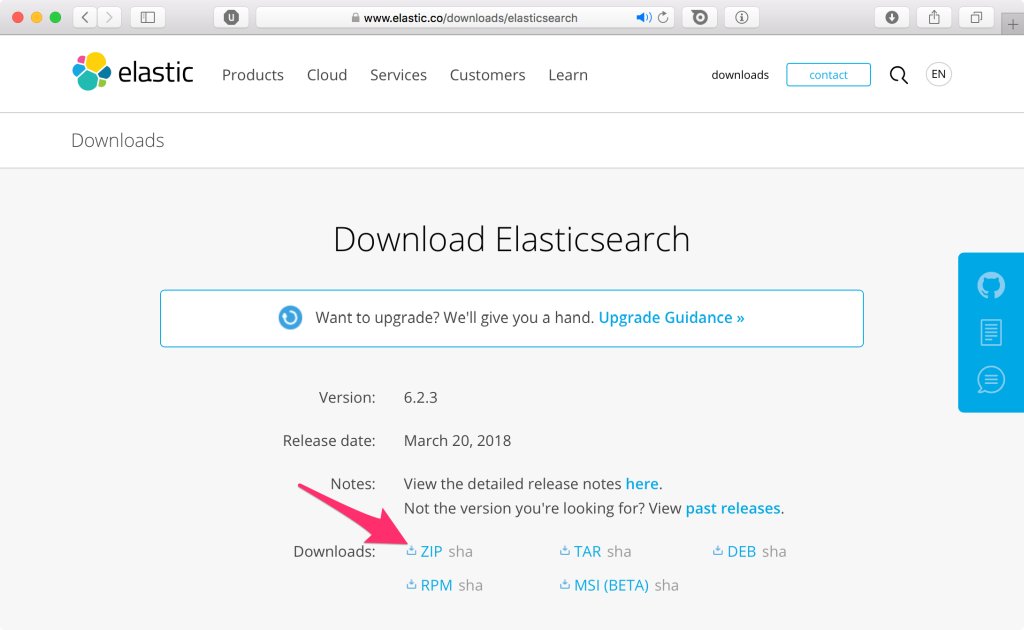
Stažený archiv rozbalte do libovolné složky, její obsah bude vypadat následovně:

Celý postup je také možné provést z terminálu následujícími příkazy:
# stažení archivu wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.zip # rozbalení staženého archivu unzip elasticsearch-6.2.3.zip
Základní konfigurace
Nyní je možné nastavit základní parametry Elasticsearch editací souboru elasticsearch.yml, který se nachází ve složce config. První úpravou je nastavení cluster.name, čímž docílíme toho, že se nebude snažit spuštěný Elasticsearch připojit na jiné nepřejmenované běžící instance Elasticsearch. Výsledná podoba souboru je pak následující:
# soubor elasticsearch-6.2.3/config/elasticsearch.yml cluster.name: elasticsearch-tutorial
Pokud instalujete Elasticsearch pomocí konzolových příkazů ze staženého repozitáře, lze použít již připravený konfigurační soubor - stačí jej nakopírovat na správné místo příkazem:
cp elasticsearch.yml elasticsearch-6.2.3/config/
Editace souboru elasticsearch.yml není jediným možným způsobem konfigurace Elasticsearch, podrobnější informace jsou k nalezení v oficiální dokumentaci.
Instalace českého slovníku
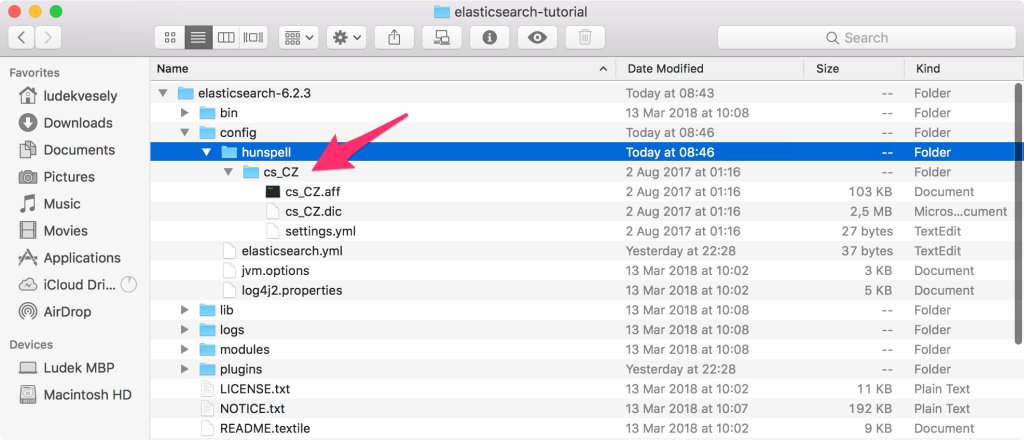
Pro správnou funkci češtiny při vyhledávání je třeba nainstalovat český slovník. Stačí stáhnout příslušné soubory projektu Hunspell. K dispozici jsou pro řadu jazyků, české jsou připraveny na GitHubu v repozitáři tohoto tutoriálu. Slovník je tvořen třemi soubory cs_CZ.aff, cs_CZ.dic a settings.yml, které uložte do složky elasticsearch-6.2.3/config/hunspell/cs_CZ.
Instalace pluginu ICU
Posledním doplňkem pro korektní funkčnost češtiny je plugin ICU, který umožňuje správnou práci s kódováním Unicode v českém jazyce. Jeho instalace je možná zadáním následujícího příkazu:
elasticsearch-6.2.3/bin/elasticsearch-plugin install analysis-icu
Spuštění Elasticsearch
Nyní nám již nebrání nic ve spuštění Elasticsearch - stačí spustit soubor elasticsearch umístěný ve složce bin:
elasticsearch-6.2.3/bin/elasticsearch
Následně se zobrazí log běžícího Elasticsearch. Spuštění chvíli trvá, jakmile se v logu objeví, že se jeho stav změnil z red na green, můžete jeho spuštění ověřit otevřením adresy http://localhost:9200 ve webovém prohlížeči.

Nástroje pro práci s Elasticsearch
Abychom mohli s Elasticsearch rozumně pracovat (psát dotazy pro ukládání dokumentů nebo vyhledávání), je vhodné nainstalovat další nástroje, které tuto práci usnadní.
Kibana
Kibana je grafické rozhraní, které se umí připojit na Elasticsearch a vizualizovat data, která jsou v něm uložena. Primárním účelem tohoto nástroje je rychlé vyhledávání v uložených datech, vytváření vizualizací (grafů a tabulek) a jejich skládání do komplexních dashboardů. Její součástí je však také editor, který umožňuje pohodlné vykonávání příkazů, zvýrazňuje syntaxi, a při psaní dotazů pomáhá našeptáváním.
Kibana je ke stažení na adrese www.elastic.co/downloads/kibana. Zde stáhněte verzi dle vašeho operačního systému.

Stažený archiv rozbalte, spustitelný soubor je opět ve složce bin.

Stažení a spuštění je možné opět provést také z terminálu. Použijte k tomu následující příkazy:
# stažení wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.3-darwin-x86_64.tar.gz # rozbalení archivu tar xzf kibana-6.2.3-darwin-x86_64.tar.gz # spuštění kibana-6.2.3-darwin-x86_64/bin/kibana
Po jejich provedení můžete otevřít adresu http://localhost:5601 ve svém webovém prohlížeči. Zobrazí se úvodní stránka - rozcestník vedoucí na další stránky Kibany, přičemž nás v tuto chvíli zajímá Console.
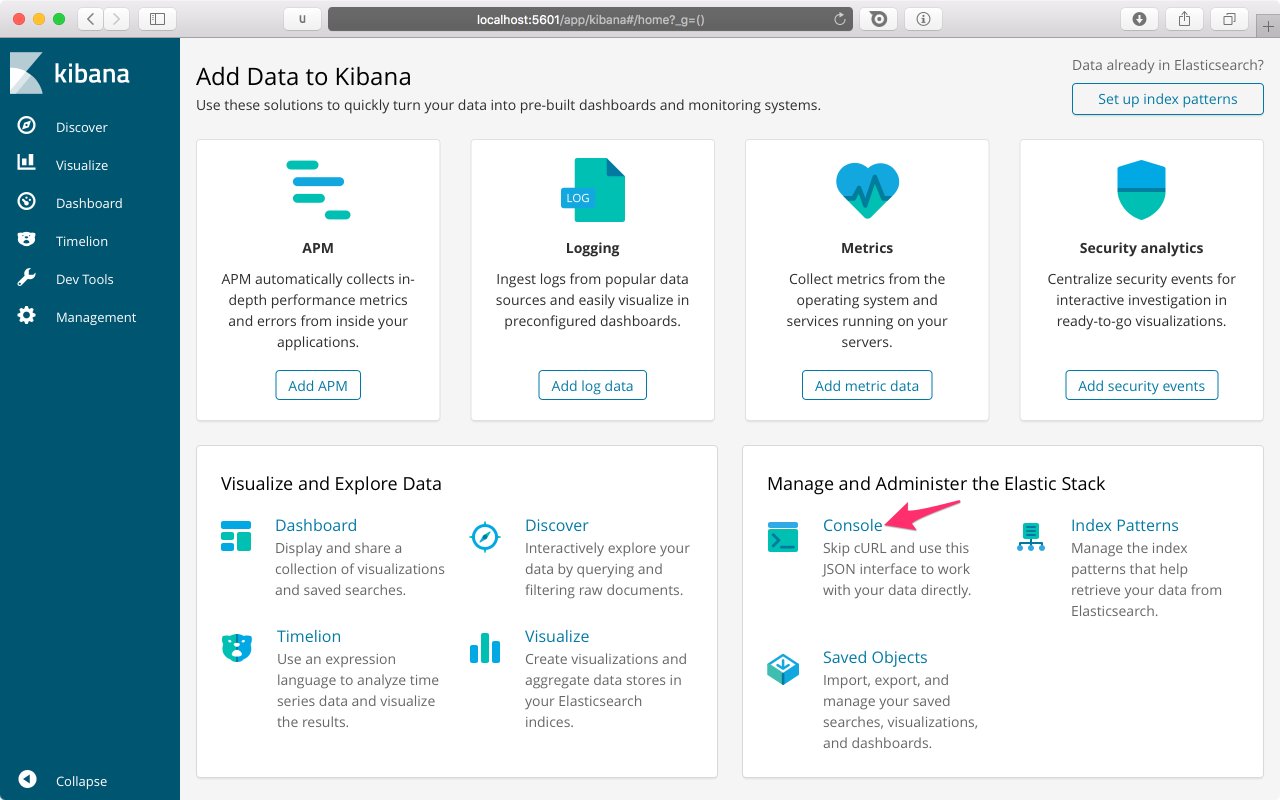
Nyní jste se přepnuli do Dev Tools, konkrétně do části Console. Zde již můžete vytvářet a spouštět dotazy, využívat našeptávání a zvýrazňování syntaxe. Můžete zkusit spustit předpřipravený dotaz GET _search, který provede vyhledávání nad všemi dokumenty uloženými v Elasticsearch. V pravé části okna je vidět, že bylo nalezeno 0 dokumentů ("total": 0), protože jsme do Elasticsearch zatím nic neuložili.

Cerebro
Posledním instalovaným nástrojem je Cerebro. Sice není pro vývoj nezbytně nutný, nabízí však funkce, kterými Kibana sama o sobě nedisponuje - umožňuje především správu a monitoring clusteru, tedy zobrazení jeho aktuálního stavu a úpravu konfigurace. Je však užitečný i pro lokální vývoj, kdy graficky zobrazí všechny dostupné indexy. Lepší možnosti monitoringu sice poskytuje X-pack, který jde do Kibany doinstalovat, je však placený. Cerebro je kompletně zdarma.
Pro stažení je třeba přejít na stránku releases na GitHubu, kde je ke stažení ZIP archiv.

Stažený soubor rozbalte, spustitelný soubor cerebro se nachází ve složce bin. Spustit jej můžete z terminálu příkazem cerebro-0.7.2/bin/cerebro (pokud by nešel spustit, nastavte mu odpovídající práva). Po spuštění je k dispozici grafické rozhraní na adrese http://localhost:9000. Zde je nutné nastavit, kde je dostupný Elasticsearch. Zadejte http://localhost:9200 a pokračujte tlačítkem Connect.

Po připojení k Elasticsearch je vidět základní statistika - počty indexů, dokumentů, nebo vytížení hardware.

Kompletní stažení a instalaci je opět možné provést z terminálu ve složce elasticsearch-tutorial:
# stažení archivu wget https://github.com/lmenezes/cerebro/releases/download/v0.7.2/cerebro-0.7.2.zip # rozbalení archivu unzip cerebro-0.7.2.zip # spuštění cerebro-0.7.2/bin/cerebro
Výsledný skript pro instalaci
Veškeré výše provedené kroky jsem sepsal do skriptu install.sh, po jehož spuštění by měl být korektně nainstalovaný Elasticsearch včetně všech pluginů a podpůrných nástrojů. Pokud jste se tedy ztratili v některém z výše uvedených kroků, zde jsou uvedeny veškeré potřebné příkazy ve správném pořadí.
Po úspěšné instalaci je možné použít skript start.sh, který spustí všechny stažené nástroje. Kompletní instalace a spuštění veškerých potřebných nástrojů tedy vypadá následovně:
git clone git@githubcom:ludekvesely/elasticsearch-tutorial.git
cd elasticsearch-tutorial
./install.sh
./start.sh
Instalace pomocí Dockeru
Pokud máte nainstalovaný Docker a nástroj docker-compose, je situace o něco jednodušší. Stažený repozitář obsahuje soubor docker-compose.yml, ve kterém je definované, jak jednotlivé kontejnery vytvořit. Příkazem docker-compose up se tedy vytvoří a spustí vše potřebné (Elasticsearch s připravenými slovníky a pluginy, Kibana, Cerebro). Celý postup od klonování repozitáře z GitHubu vypadá následovně:
git clone git@githubcom:ludekvesely/elasticsearch-tutorial.git
cd elasticsearch-tutorial
docker-compose up
Po spuštění jsou k dispozici všechny služby na stejných portech jako při nativní instalaci. Po skončení práce je možné celý stack zastavit příkazem docker-compose stop, případně kompletně smazat příkazem docker-compose rm.
Od výše uvedeného postupu se liší pouze konfigurace nástroje Cerebro - neměl by se připojovat na http://localhost:9000, ale na http://elasticsearch:9000. Také v Kibaně bude k dispozici více pluginů - defaultně je zde totiž povolený x-pack.
Instalace ve Windows
Ve Windows možná nemáte dostupné všechny nástroje pro stažení a spuštění Elasticsearch, případně dáváte přednost grafickému rozhraní při instalaci. Pro tento případ je k dispozici MSI instalátor, který vás instalací a konfigurací provede. Podrobný návod jak jej použít je k dispozici v dokumentaci Elasticsearch.
Shrnutí
V této kapitole jsme stáhnuli Elasticsearch, doinstalovali doplňky nutné pro správnou funkci českého vyhledávání a následně jej spustili. Z tohoto stavu vychází další díly tohoto seriálu. Nyní můžeme přejít k ukládání prvních dokumentů v následující kapitole.