Specializuji se na Elasticsearch a jsem fanouškem DevOps. Nabízím konzultace a školení Elasticsearch - pokud jej chcete poznat důkladněji, zjistit, zda se hodí pro váš projekt, nebo uspořádat školení ve vaší firmě, neváhejte se mi ozvat.
Předpokladem je mít spuštěný Elasticsearch a Kibanu - postup případné instalace naleznete v předchozí kapitole.
REST API
S Elasticsearch se komunikuje prostřednictvím REST API. Díky tomu je možné se dotazovat na data bez nutnosti instalace speciálního klienta, některé dotazy je možné provést pouhým zadáním odpovídající URL do webového prohlížeče. Pro ostatní úkony lze použít například konzolový nástroj curl. Veškerá data jsou odesílána a přijímána ve formátu JSON. Pro efektivní práci je však vhodnější použít některý z nástrojů s grafickým rozhraním jako jsou Postman nebo Kibana.
Kibana
V následujících příkladech budu veškeré dotazy provádět prostřednictvím nástroje Kibana. Umožňuje totiž zvýraznění syntaxe, automatické formátování dotazu, našeptávání při formulaci dotazu a procházení historie provedených dotazů. Pro dotazování se Elasticsearch je to aktuálně asi nejlepší nástroj.
Otevřete ve webovém prohlížeči http://localhost:5601 a přejděte na záložku Dev Tools v levém menu. Pokud jste zde prvně, zobrazí se rychlá nápověda - pokračujte kliknutím na modré tlačítko Get to work. Nyní jsou k dispozici dva panely - v levém je možné psát dotaz, v pravém jsou následně vidět odpovědi. Napsaný dotaz je možné spustit buď kliknutím na zelenou šipku, nebo klávesovou zkratkou CMD + Enter v případě OS X. Zkusme rovnou spustit připravený dotaz GET _search. Ten provede vyhledání všech dokumentů, které jsou v Elasticsearch uloženy.

Stav clusteru
Ještě než začneme do Elasticsearch ukládat data, můžeme zjistit, jak vypadá celý cluster (v našem případě tvořený jediným nodem). Stavem je myšleno jednak to, zda Elasticsearch jako takový běží v pořádku bez chyb, jednak také to, jaké indexy a typy dokumentů obsahuje. V dokumentaci je pro zjištění stavu doporučováno využít dotazů:
GET _cat/health?v GET _cat/indices?v
Ty však nevrací data v přehledné podobě. Pro tento účel je přehlednější využít zobrazení stavu v nástroji Cerebro, dostupném na adrese http://localhost:9000.
Vytvoření indexu
Nejprve je nutné vytvořit index, aby bylo kam data vůbec ukládat. To lze provést HTTP metodou PUT následovanou názvem indexu a jeho nastavením. Vytvořme index products, do kterého budeme ukládat produkty, které budeme následně vyhledávat.
PUT products
{
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0
}
}
}
Tento příkaz spusťte v Kibaně, vytvoří se tak index s názvem products. Vytvořený index bude mít podle použitého nastavení jeden shard a žádné repliky. Zjednodušeně řečeno s tímto nastavením nemůže docházet k žádné replikaci dat, což je pro lokální vývoj na jednom stroji v pořádku. V produkčním prostředí by pak bylo nastavení odlišné v závislosti na dostupném hardware - k tomu se dostaneme v pozdějších kapitolách seriálu.
Při spouštění příkazu v Kibaně je možné psát více dotazů pod sebe. Můžeme tak mít rozpracovaných více dotazů a spouštět je, aniž bychom museli otevírat nové okno prohlížeče. Lze tak spustit výše uvedený dotaz a následně zkontrolovat výsledek provedené operace dalším dotazem. Například nastavení vytvořeného indexu ověříme dotazem GET products/_settings. Pokud neproběhl podle našich představ, lze index smazat pomocí DELETE products a pokračovat úpravou předchozích příkazů:
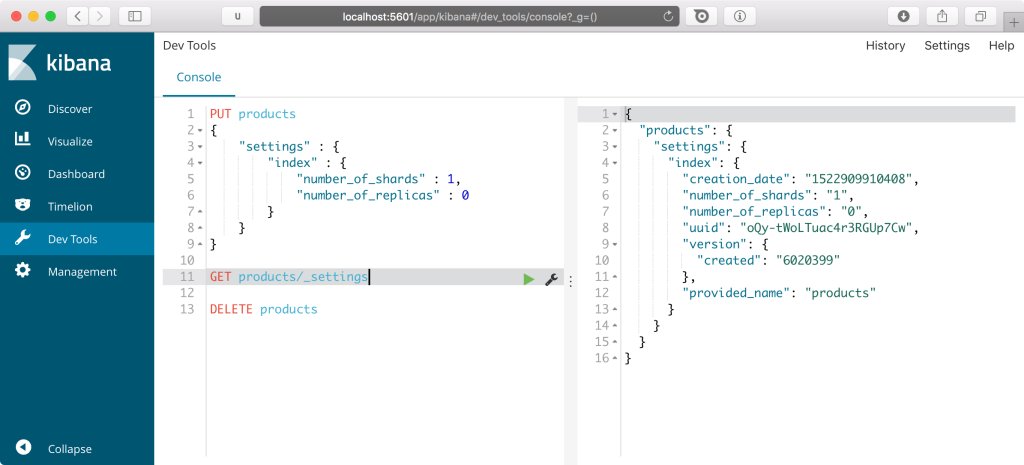
Provedené dotazy je možné zobrazit po kliknutí na History v pravém horním rohu Kibany. Není tak problém se vrátit k dříve provedenému tvaru dotazu a na něm dále pracovat.
Stav vytvořených indexů je však daleko přehlednější sledovat prostřednictvím nástroje Cerebro. Přejděte na URL http://localhost:9000, zobrazí se veškeré potřebné informace o clusteru:

Pro nás je v tuto chvíli důležitá tabulka obsahující vytvořené indexy. V této tabulce je vidět vytvořený index products tvořený jediným shardem. Pokud kliknete na dropdown vedle názvu indexu, zobrazí se menu vedoucí na zobrazení nastavení indexu, jeho editaci, statistiky a další možnosti. Cerebro nedisponuje ničím, co by Elasticsearch sám o sobě neuměl, jen jsou data graficky vizualizována a editace řady nastavení je možná prostřednictvím připravených formulářů. Pod názvem indexu můžeme vidět počet vytvořených shardů a replik, počet dokumentů v indexu a jeho velikost. Důležitý je také zelený pruh v záhlaví, který značí, že je celý cluster v pořádku.
Vytvoření mapování
Elasticsearch je bezschémový, což znamená, že při ukládání dokumentů není nutné předem definovat jejich podobu - vytvoří se automaticky při indexaci dokumentů. V praxi však většinou budeme schéma dokumentů chtít definovat předem. Důvod je prostý - s každým polem budeme chtít pracovat jiným způsobem, což Elasticsearch nemůže předem vědět. Například pokud v názvu produktu budeme chtít vyhledávat fulltextově, ale název výrobce budeme chtít vyhledat jen podle přesné shody, bylo by neefektivní obě pole ukládat zpracovaná stejným způsobem.
Pro tento účel je nutné nejprve vytvořit mapování (mapping) - definovat strukturu dokumentů. Stále pak lze indexovat dokumenty, které mají nová pole, která nejsou v mapování popsaná. V jednom indexu však musí mít jedno pole stále stejný datový typ, jinak se nezdaří ukládání nového dokumentu. Při vytváření mapování je třeba určit, pro jaký index a typ je vytvářeno, jaká pole jakých datových typů obsahuje a jak jsou případně indexována pole pro fulltextové vyhledávání.
Vytvoření jednoduchého mapování produktů by mohlo vypadat následovně:
PUT products/_mapping/products
{
"products": {
"properties": {
"id": {
"type": "integer"
},
"title": {
"type": "text"
},
"brand": {
"type": "keyword"
}
}
}
}
Zde vytváříme v indexu products typ products. V tomto typu budou ukládány dokumenty obsahující celočíselné id, titulek (title) ukládaný jako text a název značky brand ukládaný jako keyword. V obou případech (text i keyword) jde o textový řetězec (string), v prvním případě je však předpokládáno fulltextové vyhledávání a string je tak ukládán zpracovaný pro tento účel. V druhém případě je text uložen tak jak je - předpokládá se vyhledávání podle přesné shody (na filtraci dle výrobců bude na webu použit checkbox, ne textový input).
Uložení dokumentu
Nyní lze do vytvořeného indexu uložit dokumenty, které budeme následně vyhledávat. Dokument lze uložit následujícím způsobem:
POST products/products
{
"id": 1,
"title": "Lednička Calex",
"brand": "Calex"
}
POST products/products
{
"id": 2,
"title": "Lednička Gorenje",
"brand": "Gorenje"
}
Uložené dokumenty můžeme následně vyhledat pomocí GET /products/products/_search:

Při ukladání metodou POST jsou vždy vytvářeny nové dokumenty s automaticky generovaným unikátním _id. Pokud bychom chtěli použít naše id, je třeba dotaz modifikovat použitím metody PUT:
PUT products/products/1
{
"id": 1,
"title": "Lednička Calex",
"brand": "Calex"
}
PUT products/products/2
{
"id": 2,
"title": "Lednička Gorenje",
"brand": "Gorenje"
}
To, že byly dokumenty uloženy, lze také zkontrolovat v Cerebro - pod názvem indexu products přibude informace o počtu produktů: docs: 2.
Vyhledání dokumentu
Důkladně se fulltextovému vyhledávání věnuji v následující kapitole, v tuto chvíli vyhledáme uložené dokumenty pouze za účelem pochopení formulace vyhledávání.
Při vyhledávání je odesílán GET požadavek na endpoint http://localhost:9200/products/products/_search, kde products označuje nejprve název indexu, poté název typu. Název typu i indexu je možné vynechat - pak bude vyhledáváno v celém indexu, respektive v celém clusteru. V aktuální podobě by byly nalezeny veškeré dokumenty, pro skutečné vyhledávání je třeba formulovat tvar dotazu. Pokud bychom chtěli vyhledávát výraz gorenje v titulcích produktů, dotaz by vypadal následovně:
GET products/products/_search
{
"query": {
"match": {
"title": "gorenje"
}
}
}
Zde tento výsledek vyhledáváme fulltextově a pouze v titulku. Díky tomu byl nalezen právě jeden odpovídající produkt, nezávisle na velikosti písmen. Pokud byste však hledali lednicka, nebude nalezen žádný produkt. To z důvodu použití výchozího nastavení, kdy Elasticsearch neví, že má pracovat s češtinou.
Mohli bychom chtít vyhledat i podle názvu značky uloženém v poli brand. V tomto případě nás zajímá pouze přesná shoda, navíc je název značky uložen jako keyword. Proto použijeme term namísto match:
GET products/products/_search
{
"query": {
"term": {
"brand": "Gorenje"
}
}
}
Rozdíl mezi dotazy typu match a term by se dal připodobnit k otázce, zda produkt odpovídá danému výrazu (ano nebo ne → term), nebo jako hodně odpovídá danému výrazu (match). V druhém případě navíc obdržíme i hodnotu, jakou dokument hledanému výrazu odpovídá (skóre).
Tvar odpovědi
Pro výše provedené dotazy obdržíme následující odpověď:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.6931472,
"hits": [
{
"_index": "products",
"_type": "products",
"_id": "AV54Ufs6nieqNAkX7QD5",
"_score": 0.6931472,
"_source": {
"id": 2,
"title": "Lednička Gorenje",
"brand": "Gorenje"
}
}
]
}
}
Response shora obsahuje:
took: Čas v ms, který zabralo vykonání dotazutimed_out: Informace, zda se vše stihlo v časovém limitu_shards: Informace o shardech, na nichž byl dotaz vykonán_hits: Výsledky vyhledávání (nalezené dokumenty)
Pole _hits pak obsahuje pole, v němž je každý prvek tvořen:
_index: Index, ve kterém je nalezený dokument uložen_type: Typ, ve kterém je dokument uložen_id: ID uloženého dokumentu_score: Míra, kterou dokument odpovídá dotazu_source: Uložený dokument
Formát query
Při vyhledávání v Elasticsearch však budeme chtít s výsledky dále manipulovat - řadit je, stránkovat. Samotný dotaz je tak nutné rozšířit o další části, přičemž mezi nejčastěji používané patří:
query: Samotný vyhledávací dotazsize: Počet vrácených dokumentů, obdoba LIMIT z SQL, výchozí hodnota je10from: Offset při vracení dokumentů, obdoba OFFSET z SQLsort: Definice způsobu řazení výsledkůaggs: Agregace - výpočty nad všemi dokumenty odpovídající dotazu (minimální/maximální cena, výpis značek atd.)
Typický dotaz do Elasticsearch obsahující výše uvedená pole může vypadat následovně:
GET products/products/_search
{
"query": {
"match": {
"title": "Calex"
}
},
"size": 5,
"from": 0,
"sort": [
{
"id": "asc"
}
],
"aggs": {
"ids": {
"terms": {
"field": "brand.keyword"
}
}
}
}
Po jeho spuštění obdržíme prvních maximálně 5 nalezených produktů, seřazených podle id. Dále v poli aggs obdržíme seznam všech dostupných značek.

V tuto chvíli umíme spouštět dotazy do Elasticsearch vytvářet dokumenty a následně je vyhledat. V následující kapitole se dozvíte, jak dát dohromady fulltextové vyhledávání v českém jazyce.